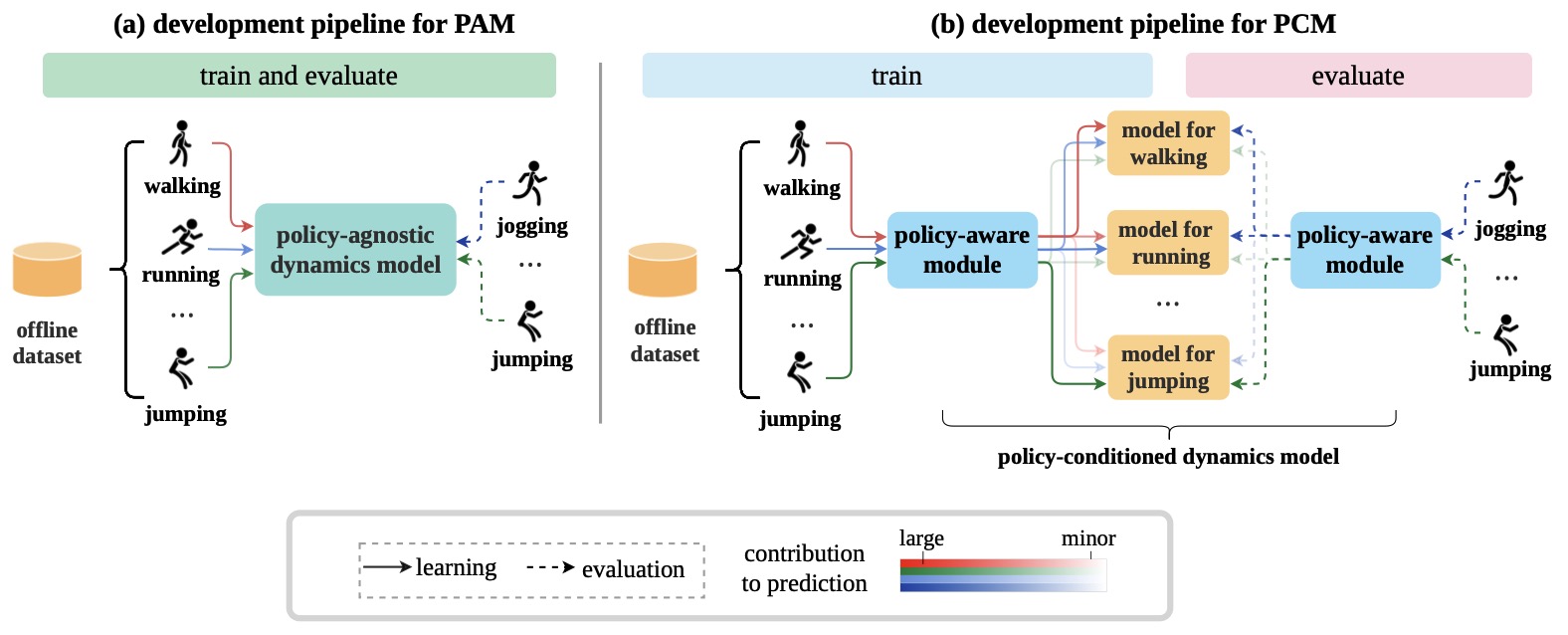
Method: Policy-conditioned Models
A. Value Gaps between True Dynamics and a Learned Model
The value gaps between true dynamcis \(T^*\) and a learned model \(\hat T\) is upper bounded by
$$ |V^\pi_{T^*} - V^\pi_{\hat T}| \leq \frac{2\gamma R_{\max}}{(1-\gamma)^2}l(\textcolor{red}{\pi}, T^*, \hat T) $$
where \( l(\pi,T^*,\hat T)=\mathbb E_{s,a\sim\rho^\pi}D_{TV}(T^*(\cdot|s,a),\hat T(\cdot|s,a)) \) is the model error under the visitation distribution of the target policy \(\pi\).
This implies that as long as we reduce the model error under the target policy's distribution \(\rho^\pi\), we can guarantee the reduce of the corresponding value gaps.
However, since the target policy's visitation distirbution is not directly accessible, previous work
(Janner 2019)
further relaxes the bound to the model error under training distribution:
$$ |V^\pi_{T^*} - V^\pi_{\hat T}| \leq \frac{2\gamma R_{\max}}{(1-\gamma)^2}l(\textcolor{red}{\mathcal D}, T^*, \hat T) +\frac{4R_{\max}}{(1-\gamma)^2}\sum_{i=1}^n w_i\max_s D_{TV}(\pi(\cdot|s),\mu_i(\cdot|s)) $$
where \( l(\pi,T^*,\hat T)=\mathbb E_{s,a\sim\mathcal D}D_{TV}(T^*(\cdot|s,a),\hat T(\cdot|s,a)) \) is the model error under the training data distribution \(\mathcal D\), and the training data are collected by a set of behavior policies \(\{\mu_i\}_{i=1}^n\), with corresponding propotion \(w_i\).
This intorduces additional policy divergence terms, irrevalent to the learned dynamics model, which just suggests minimizing the training training model error but ignores the dynamcis model's generalization to the target policies.
In contrast, we explicitly consider the dynamics model's generalization to different policies via a meta optimization formulation by conditioning the dynamics models on policies.
B. Policy-conditioned Model Learning
Conventional dynamcis model learning ignores the data source of each experience trajectory and directly learns a model from the mixed dataset, which we name Policy-agnoistic Models (PAM). Instead we propose to learn Policy-Conditioned Models (PCM) to adapt to different policies:
$$
\hat F=\arg\min_{F\in\mathcal F}\sum_{i}w_i l(\mu_i,T^*,T_{F(\mu_i)}),
$$
here \(F\) is a policy-aware module mapping each policy to model parameters, optimized by minimizing the model error between true dyanmics \(T^*\) and the models \(T_{F(\mu_i)}\) conditioned on each behavior policy \(\mu_i\) within the dataset.
In practice, we use a RNN-based encoder module \(q_\phi\) to implement this policy-aware module, trained altoghter with the policy-conditioned model and a policy decoder:
$$
\min_{\phi,\theta,\psi} \mathbb E_{t\sim[0,H-2],\tau^{(i)}_{0:t-1}\sim \mathcal D}[-\log T_\psi (s_{t+1}|s_t,a_t,q_\phi(\tau^{(j)}_{0:t-1}))-\lambda \mathcal R_\pi(q_\phi(\tau^{(j)}_{0:t-1}),\pi^{(j)},\theta)],
$$
where \(\mathcal R_{\pi}(q_\phi(\tau^{(j)}_{0:t-1}),\pi^{(j)},\theta)=\log p_\theta(a_t|s_t,q_\phi(\tau^{(j)}_{0:t-1}))\) is the policy reconstruction loss.
The learned policy embeddings serve as contexts input into the policy-conditioned models together with the current state-action.
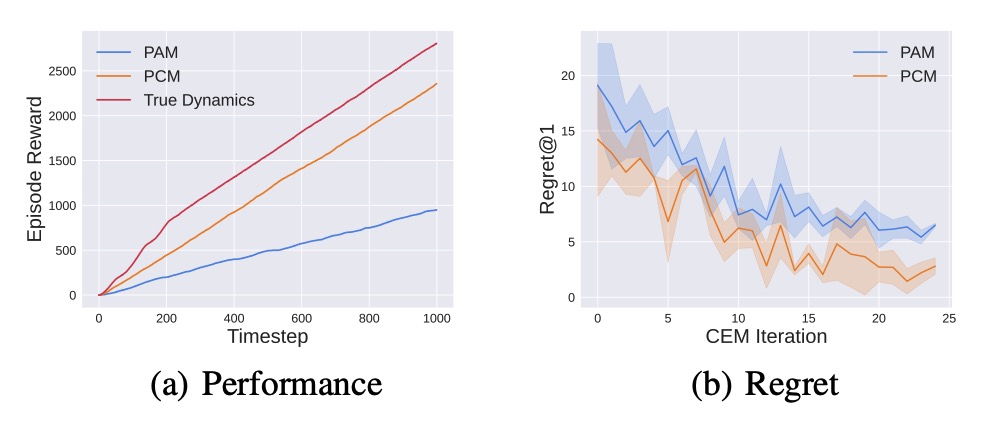
During evaluation, PCM recognizes the target policy's embedding on the fly, and adapts model to make more accurate predictions on the target distribution.
The overall development pipeline is illustrated in Figure 1.
C. Policy-conditioned Models have Lower Generalization Error
We show that the adaptation to policies reduces the PCMs' generalization error compared to conventional PAMs:
$$
l(\pi,T^*,T_{\hat F(\pi)}) \leq
\min_{\mu_i \in \Omega}\big\{\underbrace{l(\mu_i,T^*,T_{\hat F(\mu_i)})}_{\rm training~error} + \underbrace{L \cdot W_1(\rho^\pi, \rho^{\mu_i}) - C(\pi,\mu_i)}_{\rm generalization~error}\big\},
$$
where \(L\) is the Lipschitz constant of the dynamics model w.r.t. the state-action inputs, and the adaptation gain term \(C(\pi,\mu_i)\) is
$$
C(\textcolor{blue}{\pi},\textcolor{red}{\mu_i}):=l(\textcolor{blue}{\pi},T^*,T_{\hat F(\textcolor{red}{\mu_i})}) - l(\textcolor{blue}{\pi},T^*,T_{\hat F(\textcolor{blue}{\pi})}).
$$
This term summarizes the benefit brought by the policy adaptation effect, i.e., the reduced error of the target-policy-adapted model under the target distribution compared to that of the models trained under behavior policies.
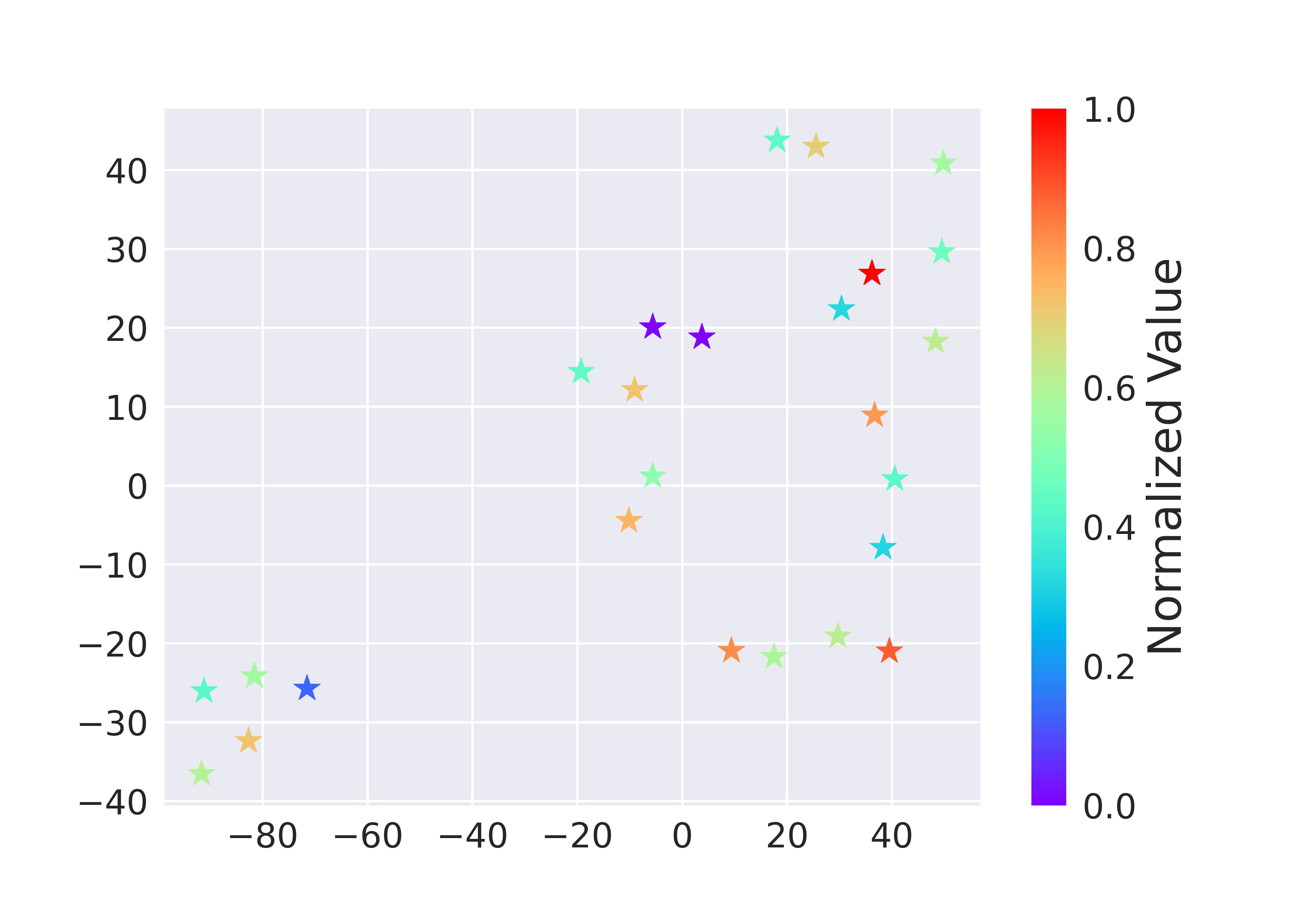
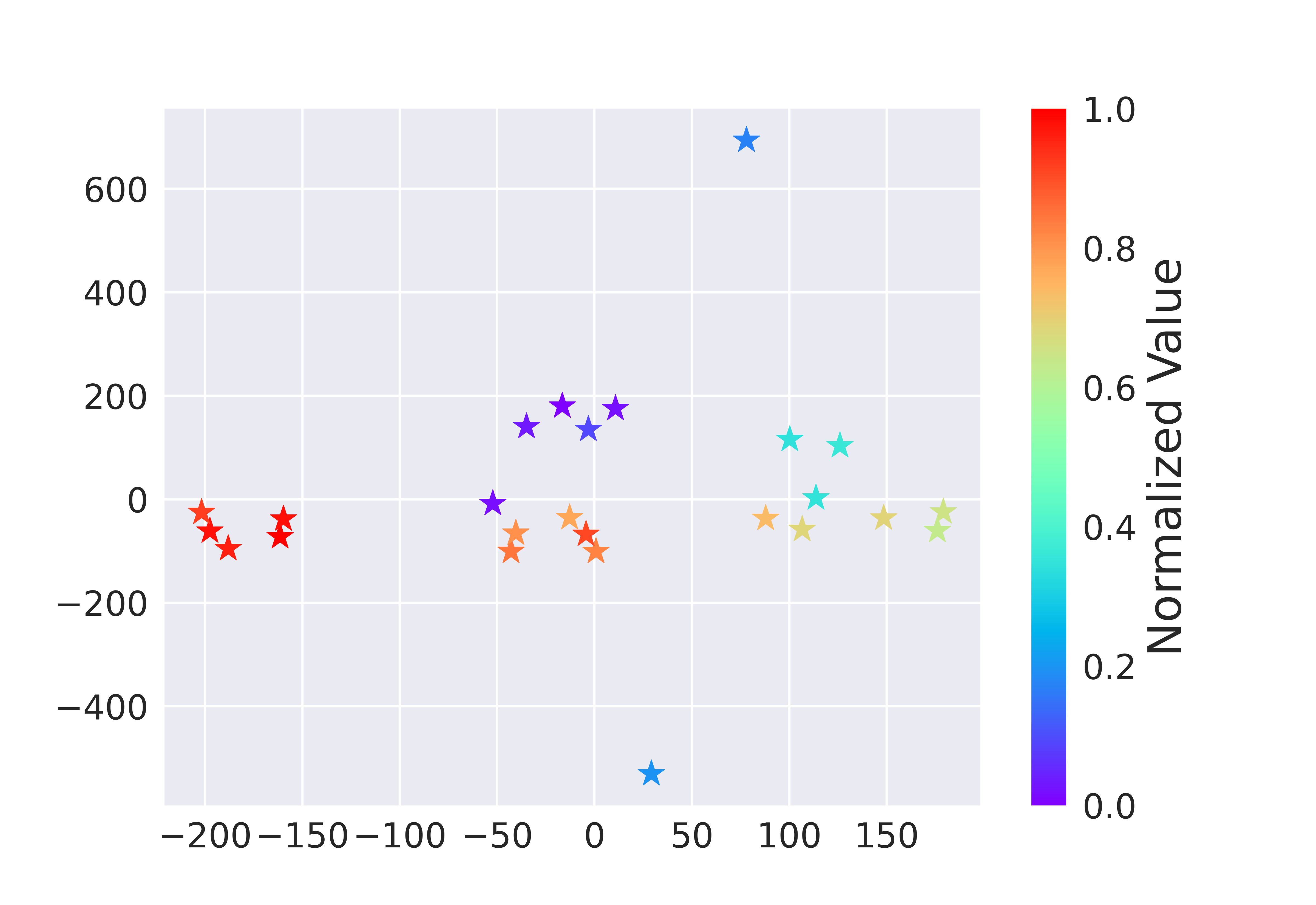
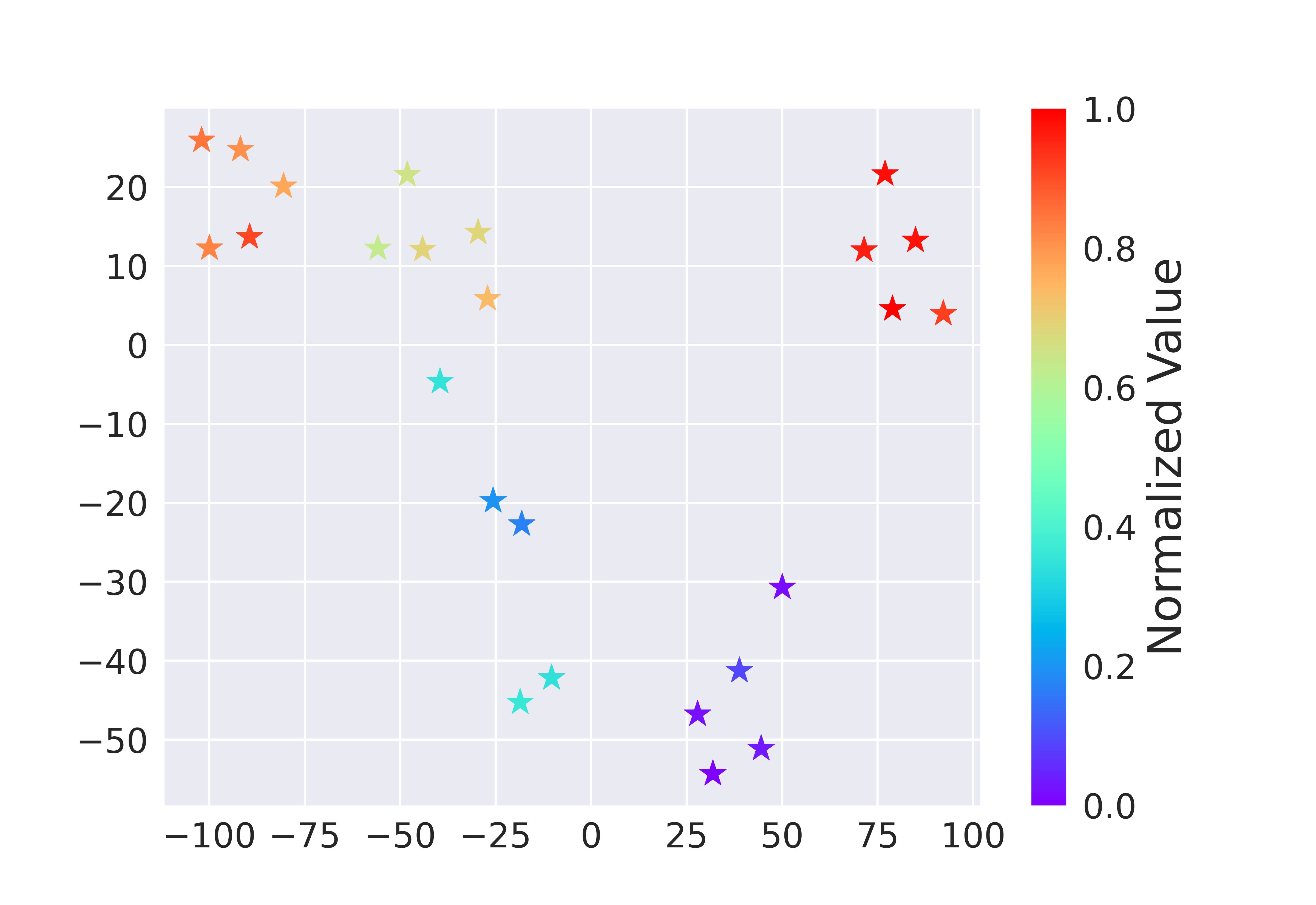
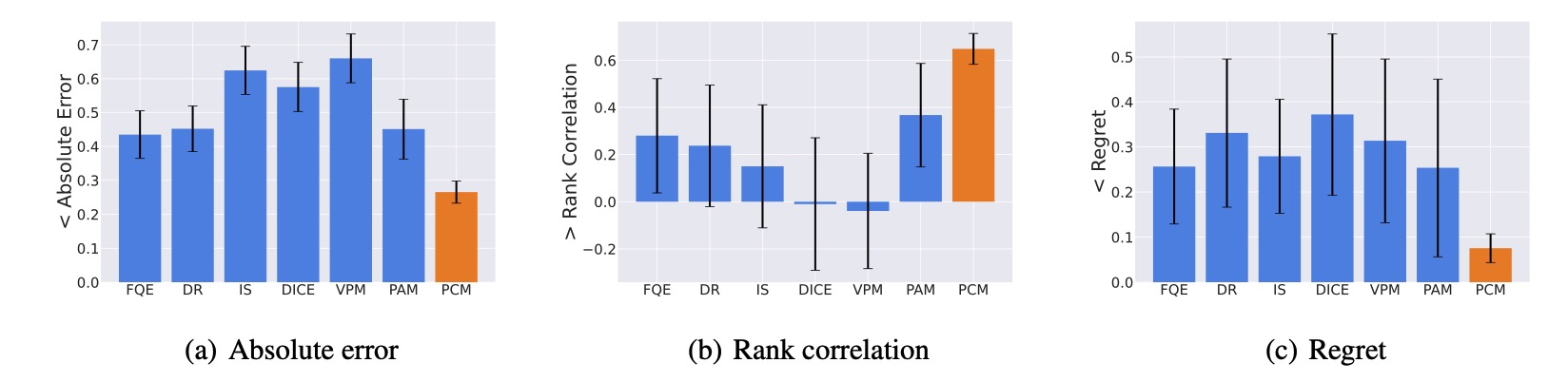
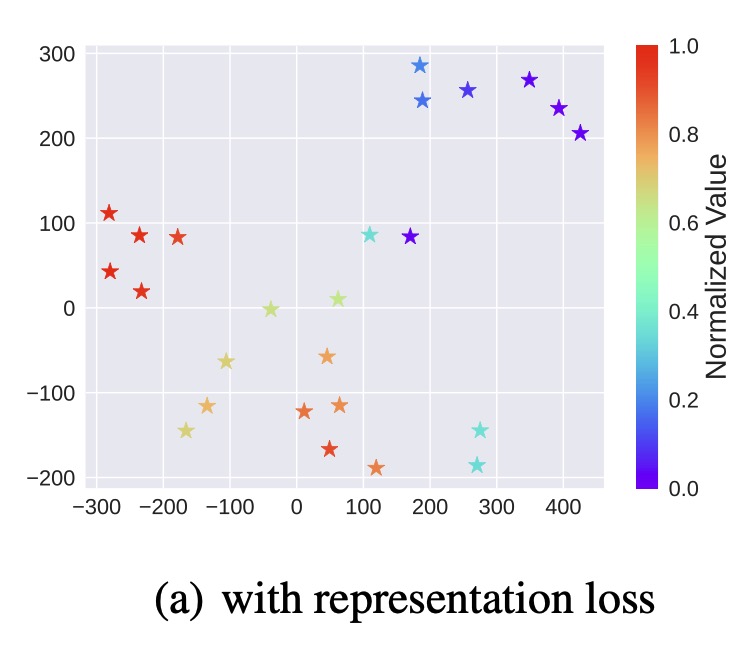
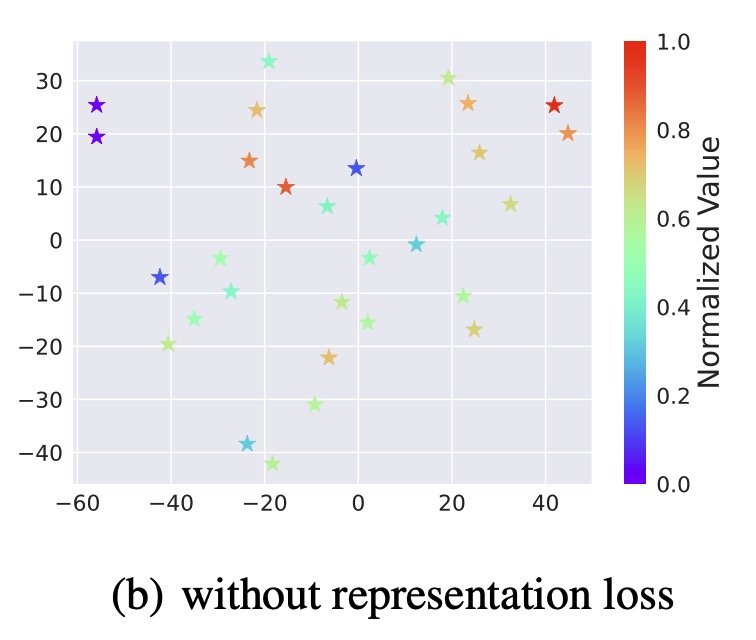
We verify this adaptation gain empirically, showing positive gains within a resonable region around the dataset, which indicates the generalizability.
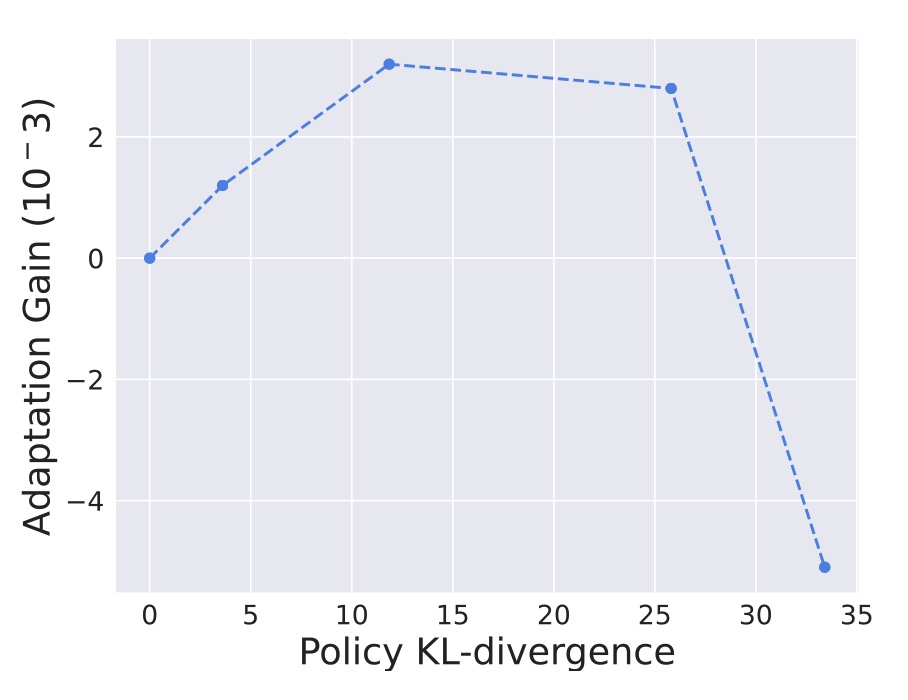
Figure 2. Illustrations of the adaptation gain of PCM for different unseen policies \(\pi\), relative to a behavior policy \(\mu_i\).